




Dans le domaine de l’intelligence artificielle, de nombreuses entreprises hésitent encore à adopter l’approche open source. Cependant, l’équipe technologique d’Alibaba franchit des étapes audacieuses en publiant récemment son modèle de génération vidéo de pointe, WanXiang. Ce modèle open source inclut non seulement le code d’inférence complet et les poids, mais aussi la licence open source la plus flexible disponible.
Les défis de la génération vidéo
Les spécialistes des modèles de génération vidéo connaissent bien leurs limites actuelles. La plupart peinent à reproduire avec précision les mouvements humains complexes comme les saltos gymniques ou les chorégraphies. Les interactions réalistes entre objets (rebonds, réactions physiques) restent aléatoires. Même les prompts textuels détaillés aboutissent souvent à une “adhésion sélective” où seul un fragment des instructions est respecté. Un modèle maîtrisant ces trois aspects simultanément est rarement open source.

L’approche révolutionnaire de WanXiang
WanXiang rompt avec les conventions. Non seulement il saisit les actions complexes (rotations, vrilles, sauts), mais il reproduit aussi des phénomènes physiques réalistes : collisions, rebonds, coupures. Il interprète avec précision les prompts textuels longs en anglais et chinois, générant des transitions scéniques fluides et des interactions entre personnages cohérentes. 
Découvrons quelques démonstrations officielles :
Démo 1 : Plongeon acrobatique
Prompt : Un homme exécute un saut de plateforme professionnel en maillot de bain rouge, corps inversé en l’air avec bras tendus et jambes jointes. La caméra suit sa chute dans le bassin, capturant l’éclaboussure sur fond bleu.

Démo 2 : Parcours équestre
Prompt : Un cavalier guide son cheval à travers un parcours d’obstacles. Concentré dans sa tenue professionnelle, il enchaîne les sauts avec une précision remarquable. La scène dynamique se déroule en extérieur sous une lumière naturelle intense.

Démo 3 : Combat de chats boxeurs
Prompt : Deux chats anthropomorphes en équipement de boxe s’affrontent dans un ring éclairé. La scène capture leurs mouvements rapides, coups puissants et détails d’action saisissants.

Applications concrètes de WanXiang
On pourrait questionner l’utilité d’un modèle open source si complexe. Alibaba propose deux versions : 14B et 1.3B de paramètres. La version 1.3B fonctionne sur des GPU grand public comme le 4090 avec seulement 8,2 Go de VRAM, produisant des vidéos 480P de qualité idéale pour la recherche académique et le développement de modèles dérivés.
Sur VBench, WanXiang atteint un score total de 86,22%, surpassant des modèles internationaux comme Sora, HunyuanVideo et Gen
Fonctionnalités clés de WanXiang
1. Génération de vidéo à partir de texte
La fonctionnalité “texte-vers-vidéo” est la capacité phare de WanXiang. En termes simples, elle transforme des invites textuelles en vidéos de haute qualité. Par exemple, avec une simple description, elle peut générer des effets cinématographiques, des polices spéciales ou même des logos animés. Cette flexibilité la distingue des autres modèles.
- Exemple: Dans un paysage urbain néon, le mot « Welcome » apparaît sur une enseigne devant un fond cyberpunk vibrant.

2. Génération de mouvements complexes
Les mouvements complexes constituent souvent le défi le plus difficile pour les modèles de génération vidéo. Qu’il s’agisse de rotation, de saut ou de course, même de légères erreurs peuvent ruiner le réalisme. Cependant, WanXiang excelle dans ce domaine, gérant les mouvements avec une précision remarquable.
- Exemple 1: Un basketteur saute pour marquer un panier. Le modèle capture avec précision le mouvement du joueur, du saut à la trajectoire du ballon.

- Exemple 2: Un clown passe devant une camionnette en flammes, ses mouvements exagérés et ses expressions faciales capturés dans un style cinématographique.

3. Respect des instructions textuelles longues
WanXiang ne se contente pas de traiter des invites courtes et simples. Il peut générer des scènes hautement détaillées à partir de descriptions textuelles longues, en maintenant une cohérence entre multiples sujets et actions.
- Exemple: Une scène de fête animée avec des danseurs variés, des décorations vibrantes et une ambiance festive, capturée en plan large.

4. Modélisation physique
Le modèle impressionne également par sa capacité à simuler des interactions physiques réalistes. Par exemple, lorsqu’un verre transparent de lait est renversé, WanXiang simule avec précision l’écoulement du liquide et sa tension superficielle.
- Exemple: Une fraise tombe dans un verre d’eau. Le modèle capture l’interaction entre le fruit et l’eau, mettant en valeur la physique des gouttelettes et la descente de la fraise avec un réalisme saisissant.
Les performances puissantes de WanXiang découlent de deux innovations clés : le VAE 3D causal efficace (Autoencodeur Variationnel) et le Transformateur de Diffusion Vidéo (DiT).
1. VAE 3D causal efficace
L’équipe d’Alibaba a conçu une nouvelle architecture VAE 3D spécialement adaptée à la génération vidéo. Cette innovation permet une compression plus efficace du temps et de l’espace, réduisant l’utilisation mémoire et garantissant la causalité temporelle – essentielle pour maintenir la fluidité des événements dans une vidéo.
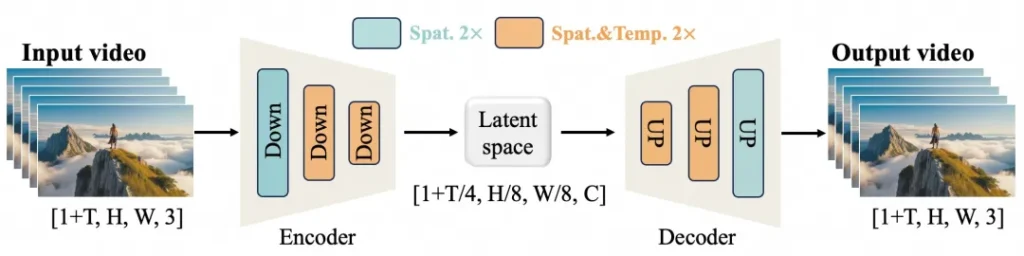
2. Transformateur de Diffusion Vidéo
WanXiang utilise également l’architecture de pointe Transformateur de Diffusion (DiT). Cette approche exploite des mécanismes d’attention complets pour modéliser les dépendances spatiales et temporelles à long terme. L’architecture du modèle, basée sur des trajectoires de bruit linéaires, l’aide à générer des vidéos avec un alignement spatio-temporel cohérent.
L’avenir des modèles open-source
Avec cette publication, le modèle WanXiang d’Alibaba établit un nouveau standard pour la génération vidéo, démontrant que les modèles open-source peuvent surpasser leurs équivalents propriétaires. Associé aux autres initiatives open-source d’Alibaba comme les modèles linguistiques Qwen, cette étape marque un moment clé dans le développement de l’IA.
En ouvrant l’accès à ces modèles puissants, Alibaba se positionne à l’avant-garde de l’innovation en IA. Leurs modèles, dont WanXiang, sont désormais disponibles sur des plateformes comme GitHub, HuggingFace et MoDa, supportant des cas d’usage variés allant de la recherche académique à la production vidéo commerciale.
Conclusion
La sortie de WanXiang révolutionne le paysage de la génération vidéo par IA. Avec sa capacité à créer des vidéos détaillées et haute qualité à partir de textes, simuler des mouvements complexes et modéliser une physique réaliste, il est prêt à transformer des industries comme la publicité, le cinéma et même le gaming. L’engagement d’Alibaba envers l’IA open-source brise les barrières et établit de nouveaux standards pour la création vidéo.









