




電玩遊戲是人工智慧的終極考場嗎?
多年來,評估AI模型始終依賴MMLU、Chatbot Arena和SWE-Bench Verified等基準測試。但隨著AI進化,就連Andrej Karpathy等專家都開始質疑這些方法是否依然有效。
他最新的擔憂?AI基準測試正逐漸失去可靠性——而更好的評估方式可能藏在電玩遊戲中。
畢竟,AI在遊戲領域早有輝煌戰績。DeepMind的AlphaGo通過擊敗圍棋冠軍改變世界。OpenAI在Dota 2的統治性表現,證明AI能在策略遊戲中超越人類玩家。 
如今,加州大學聖地牙哥分校Hao AI實驗室的研究人員更進一步。他們打造開源「遊戲代理」AI,用即時解謎遊戲測試大型語言模型(LLMs)——首個考驗是超級瑪利歐兄弟。
結果如何?Claude 3.7持續遊玩90秒——完勝OpenAI的GPT-4o,後者幾乎瞬間死亡。
Claude 3.7在超級瑪利歐完勝OpenAI與Google
已開放開源下載的GamingAgent項目,讓AI模型能用自然語言操控遊戲角色。
🔹 Claude 3.7 Sonnet堅持驚人的90秒。
🔹 GPT-4o僅20秒就死亡——被首個敵人擊敗!
🔹 Google的Gemini 1.5 Pro與Gemini 2.0表現糟糕,連基本移動都成問題。
GPT-4o:不會跳躍的AI
想像有個玩家爛到幾秒內就死亡,那就是超級瑪利歐裡的GPT-4o。
- 💀 首次嘗試:被首個敵人擊殺,完全像個新手。

- 💀 二次嘗試:幾乎沒進展,每兩步就停頓。

- 💀 三次嘗試:卡在水管下10秒後死亡。

對於自詡具備先進推理能力的AI模型,GPT-4o的表現令人震驚地糟糕。
Google的Gemini:「兩步一跳」策略
Gemini 1.5 Pro同樣在首個敵人處失敗。但二次嘗試時有所進步——撞擊?方塊並取得超級蘑菇。
不過它養成怪癖:每兩步就跳躍——無論必要與否。
- 🚀 短距離內跳躍9次

- 🚀 躍過水管、地面甚至空地

- 🚀 比GPT-4o走更遠,但仍墜入深坑

Gemini 2.0 Flash稍好些,跳躍更流暢並抵達更高平台。但仍未能逃脫第四根水管附近的深坑——終結遊戲。
Claude 3.7:超級瑪利歐神童?
與OpenAI和Google模型不同,Claude 3.7玩得像真人玩家。
- ✔ 只在必要時跳躍(避開障礙或缺口)

- ✔ 透過精準跳躍避開敵人

- ✔ 發現隱藏星星強化道具!
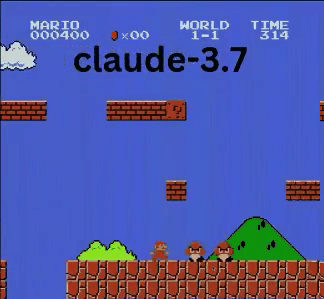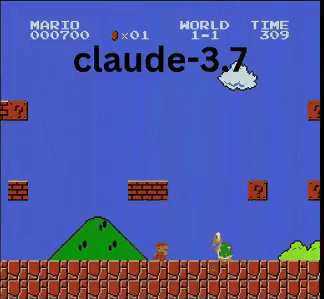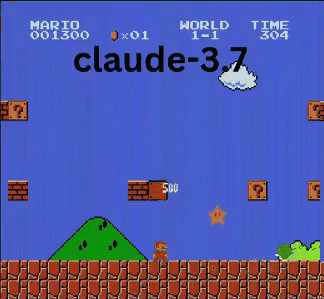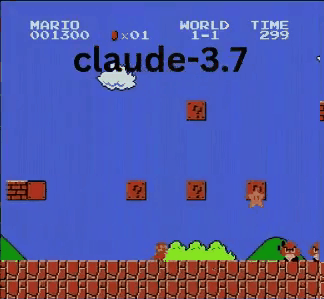
- ✔ 抵達所有AI中最遠進度
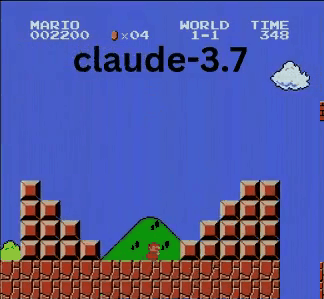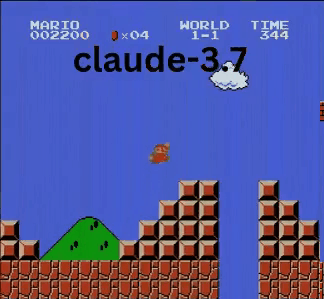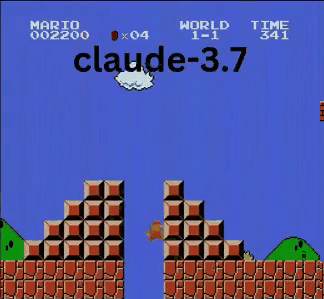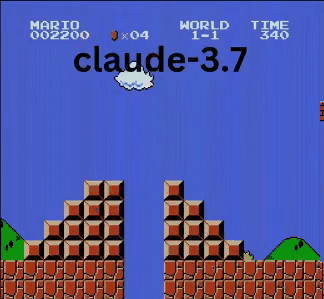
Claude 3.7甚至擊敗先前保持最佳紀錄的Gemini 2.0 Flash。當Gemini在深坑失敗時,Claude不僅通過,還獲取額外金幣並迎戰慢慢龜等新敵人。
AI能駕馭更複雜遊戲嗎?
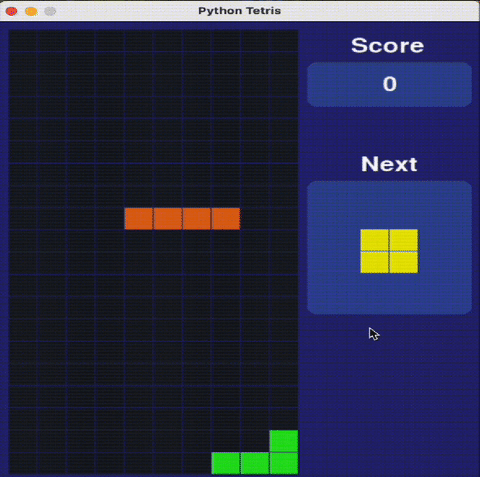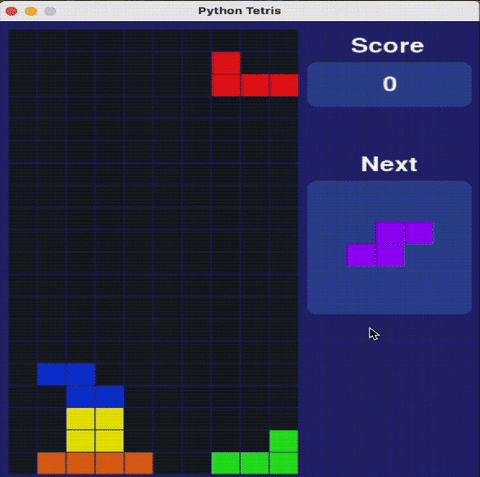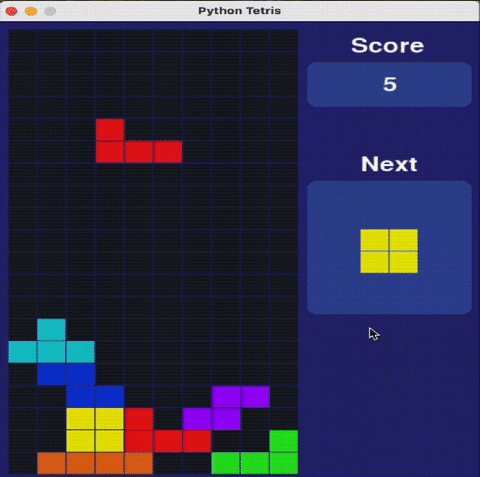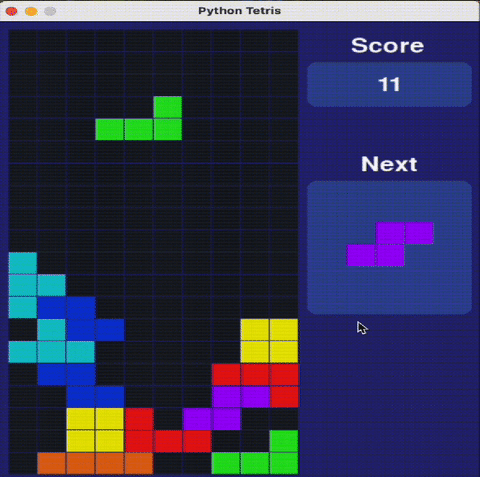
瑪利歐不是唯一測試。研究人員還用需要策略決策的經典解謎遊戲俄羅斯方塊和2048評估AI模型。
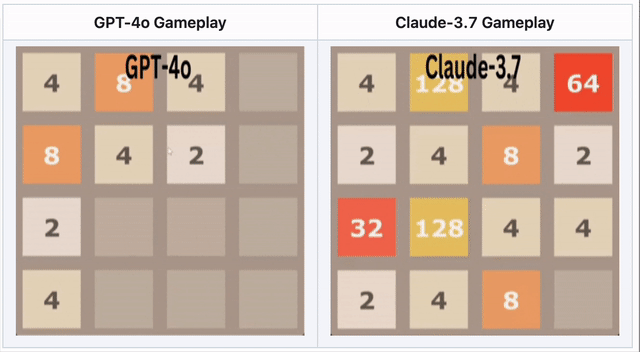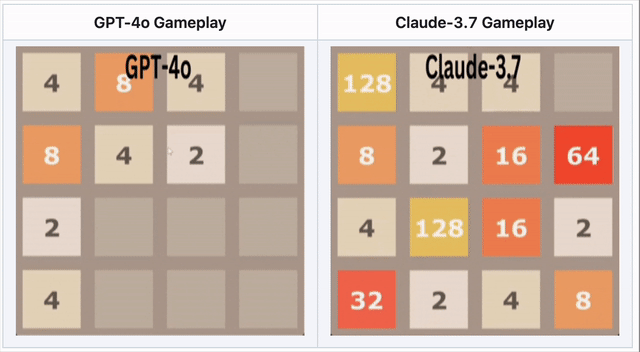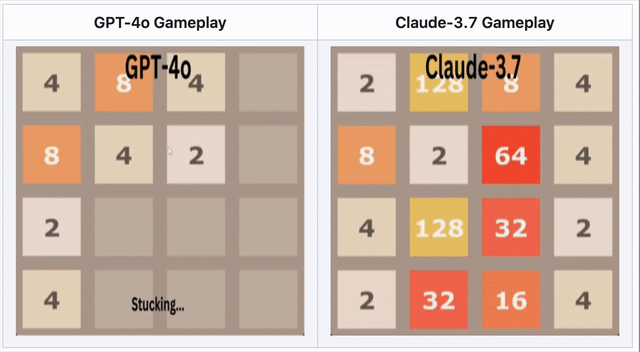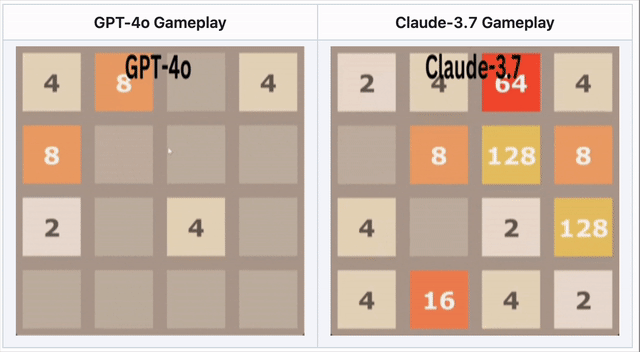
GPT-4o在2048落敗——Claude 3.7表現更佳
在數字合併遊戲2048中,AI需滑動方塊並做出策略移動。
🔹 GPT-4o過度思考導致早期失敗。
🔹 Claude 3.7堅持更久,做出更聰明方塊合併。
🔹 兩模型皆未取勝——但Claude表現優於GPT-4o。
Claude 3.7俄羅斯方塊表現驚艷專家
在俄羅斯方塊測試中,Claude 3.7展現:
✔ 合理的方塊堆疊策略
✔ 正確消除行列
✔ 存活時間長於其他AI模型
Anthropic的Alex Albert稱讚實驗時表示:
「我們應該把每款電玩都變成AI基準測試!」
遊戲是AI評估的未來嗎?
結果顯示電玩可能成為AI的下個重要基準。與傳統測試不同,遊戲需要即時決策、適應能力和操作技巧。
隨著AI模型快速進化,靜態基準可能不足以判斷真正智能。若遊戲被證實是更好指標,我們或將看到AI模型在部署前透過強化學習訓練數千款遊戲。
最終思考:Claude贏得此輪,但下一步?
Claude 3.7的優異遊戲表現暗示其推理與適應能力強於GPT-4o和Gemini。但隨著AI進化,哪個模型將率先像人類般完整通關遊戲?
隨著開源遊戲代理問世,預計將有更多AI對決電玩的戰役。誰知道呢?或許有天AI能零失誤通關超級瑪利歐——甚至擊敗人類電競選手。
在那之前,Claude仍是AI遊戲之王——而GPT-4o需要好好練習!









