




不是他們不想挖,而是他們不想挖。他們害怕繼續!
有傳言稱,當鑽探達到12262公尺時,發生了一些非常「奇怪」的事情,現場的科學家無法解釋這些事情。傳聞他們鑽進了恐怖的「地獄之門」。隨後,入口處以12噸重的鋼門封死,方圓20公里內禁止車輛、行人、飛機通行。這是真的還是假的?
這就是著名的「科拉超深鑽孔」。 
計劃開始:
讓我們回到1956年,當時蘇聯和美國正在冷戰。雖然沒有直接衝突,但兩個超級大國在各個領域都在相互競爭,包括「上天入地」。
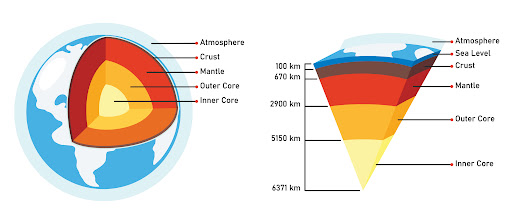
1956年,美國啟動了“莫霍爾計劃”,旨在鑽穿地殼,到達莫霍洛維奇不連續面(地殼和地幔之間的邊界,其深度從大陸上的約20-70公里到7 -7公里不等)。該計劃是使用瓜達盧佩島附近的 Glomar Challenger 鑽探船從該邊界採集岩石樣本,耗資 3 億美元。
最初的實驗鑽探取得了成功,從 183 公尺深的洋殼中取回了岩石樣本。然而,很快地人們就發現鑽探比預期更具挑戰性。

當時的一位地質學家打了個比方,將難度比喻為站在高樓上,試圖用一根又長又細的麵條鑽入下面的柏油路。顯然,所需資源將遠遠超過3億美元。由於這些挑戰,莫霍爾計畫於 1966 年被放棄。
看到美國的困難,蘇聯對這個計畫發動了猛烈的攻勢。他們的宏偉計劃就這樣開始了,代號為「地球望遠鏡計畫」。蘇聯的口號是:“挖透地球!”
1970年,蘇聯在科拉半島秘密聚集了數千名研究人員。每位研究人員每個月的薪水相當於大學教授的年薪,並提供住房,顯示出蘇聯超越美國的決心,對這個計畫投入大量資金。
如何挖掘?
根據以往的經驗,所需要的只是一台旋轉鑽機、一根非常堅固的鑽桿和一個極硬的鑽頭。這三個部件將組裝起來鑽入地球。考慮到他們的目標深度,每個部分都需要加固,但不需要太空探索所需的高科技。蘇聯認為,如果他們不能在太空(當時太空競爭非常激烈)上擊敗美國人,那麼他們在地球的挖掘上肯定會超過他們。

一切準備就緒,鑽孔開始了!
在最初階段,一切都很順利。以石油鑽探的經驗來說,幾千公尺根本不算什麼。然而,隨著鑽孔深度的增加,困難也隨之增加。但這並沒有阻止現場的科學家們,在計畫高峰期,他們得到了同時工作的16個實驗室的支持,並受到蘇聯地質部的直接監督。
直至7000米,鑽探過程相對穩定,已穿過堅硬的花崗岩層。然後,他們進入了一層不太堅固的層狀岩石,那裡有不規則的空腔。鑽柱卡住,鑽頭在回收過程中掉落。他們必須加固丟失的部分並鑽到側面。
此類事件不只一次發生,導致鑽探時間延長了數年。到1979年6月,鑽井深度超過9583米,打破了美國俄克拉荷馬州伯莎·羅傑斯超深井創下的紀錄。
1983年,鑽探深度達12066公尺時,工程暫時停止,為1984年莫斯科國際地質大會做準備。
1984年9月27日,鑽井恢復,但第一次下鑽柱時發生事故,鑽柱斷裂,5公里長的鑽柱卡住,無法恢復。他們不得不從7000公尺重新開始鑽探。
到1989年,鑽探深度達12公里。科學家預計第二年將達到 13.5 公里,兩年後將達到 15 公里。
然而1992年,當鑽探深度達到12,262公尺時,「地球望遠鏡」工程戛然而止,最深點仍停留在12,262公尺。
一夜之間,所有科學家和工程師都撤離了。鑽孔用12噸重的鋼帽密封,設備被留下。參與該計畫的人默默地回到家,拒絕討論此事。

他們為什麼停下來?
他們遇到了無法解釋的超自然現象。在12000公尺處,他們發現了一個大洞穴-一個懸崖般的洞穴。儘管進行了多次嘗試,研究人員仍無法探索洞穴的內部。他們放下了一個耐熱錄音裝置,它捕捉到了非常奇怪的聲音,例如人類的尖叫聲。在場的人稱,這些聲音就像地獄裡罪人的哭聲,彷彿無數人正遭受巨大的痛苦。
他們相信自己已經鑽穿了地球表面,進入了「地獄之門」。官方和科學研究人員不敢再繼續下去,此事被列為高度機密。
1992年全面停工後,鑽孔以12噸重的鋼門封閉,周圍20公里範圍內禁止任何車輛、行人、飛機通行。
2002年,來自俄羅斯、美國、歐洲太空總署、日本和加拿大的聯合地質和生物考察隊重新考察了科拉鑽探現場。他們驚訝地發現,這扇重達12噸的鋼門敞開著,嚴重受損,向外凸出,外面出現了裂痕。洞口周圍佈滿了神祕的痕跡,洞口冒出藍綠色的煙霧,還伴隨著不規則的聲音。

他們使用地質探測器對鑽孔入口進行了雷射掃描,發現自 1992 年上次鑽探以來,科拉遠東地區已經加深了 7,863 公尺。
用煙幕清除煙霧後,五名專家和五名守衛進入地下,到達了五百公尺深處的第一層平台。在那裡,他們遇到了奇怪的發光波和空洞的迴響。兩名工人和三名警衛在進入後五分鐘內就暈倒了,不得不被緊急送回地面。藍色火焰從深處噴湧而出,當場炸死兩人,炸傷一人重傷。十七人成功逃脫,事件立刻被掩蓋。專家被送往莫斯科接受治療,死去的警衛和專家也被秘密埋葬。俄羅斯隨後用鋼筋混凝土和鋼材重新封閉了科拉鑽孔,將半徑50公里的範圍指定為軍事禁區和禁飛區。本記述來自奧列格‧德雷夫科‧安德烈 (Oleg Derevko Andrey) 的《科拉鑽孔探險紀錄》。
但這些解釋都過於奇幻,被認為是民間傳說。
停止的真正原因是

繼續鑽探需要不斷更換鑽頭,每個鑽頭花費數萬美元,使得該項目極其昂貴。此外,提升長鑽桿、更換鑽頭以及將其放回孔中的過程非常耗時,每次往返需要 7 至 8 小時。工人們基本上從事的是重複性的、勞力密集的任務,幾乎沒有任何價值。
最終,由於資金限制,該項目被認為不值得繼續進行,因此,這個宏偉的項目結束了。
有人說,鑽「地獄之門」、錄「地獄之聲」的傳言是蘇聯故意散佈的,以此為藉口叫停該項目,因為該項目成本過高,技術難度高。這樣做是為了掩蓋他們的尷尬並轉移公眾的注意力。









