




电子游戏会成为AI的终极试金石吗?
多年来,评估AI模型一直依赖MMLU、Chatbot Arena和SWE-Bench Verified等基准测试。但随着AI的进化,就连Andrej Karpathy这样的专家也开始质疑这些方法是否仍然有效。
他最新的担忧?AI基准测试正在失去可靠性——而更好的评估方法可能藏在电子游戏里。
毕竟,AI在游戏领域早有建树。DeepMind的AlphaGo通过击败围棋冠军改变了世界。OpenAI在Dota 2中称霸,证明AI能在策略游戏中超越人类玩家。 
如今,加州大学圣地亚哥分校Hao AI实验室的研究人员更进一步。他们开发了开源“游戏代理”AI,在实时解谜游戏中测试大语言模型(LLMs)——从超级马里奥兄弟开始。
结果如何?Claude 3.7持续游戏了整整90秒——碾压了OpenAI的GPT-4o,后者几乎立即死亡。
Claude 3.7在超级马里奥中完胜OpenAI和谷歌
可通过开源下载的GamingAgent项目,允许AI模型用自然语言控制游戏角色。
🔹 Claude 3.7 Sonnet坚持了惊人的90秒。
🔹 GPT-4o仅20秒就死亡——被第一个敌人击败!
🔹 谷歌的Gemini 1.5 Pro和Gemini 2.0表现糟糕,连基本移动都困难。
GPT-4o:不会跳跃的AI
想象一个几秒内就死亡的菜鸟玩家。这就是超级马里奥里的GPT-4o。
- 💀 首次尝试:被第一个敌人击杀,完全像个新手

- 💀 第二次尝试:几乎没进展,每走两步就停顿

- 💀 第三次尝试:在管道下卡住10秒后死亡

对于标榜高级推理能力的AI模型,GPT-4o的表现糟糕得令人震惊。
谷歌Gemini:”两步一跳”策略
Gemini 1.5 Pro同样倒在了第一个敌人面前。但在第二次尝试中有所进步——顶到问号砖块并获得了超级蘑菇。
不过它养成了奇怪的习惯:每走两步就跳跃——不管是否必要。
- 🚀 短距离内跳跃9次

- 🚀 跳过管道、地面甚至空地

- 🚀 比GPT-4o走得更远,但仍掉进坑洞

Gemini 2.0 Flash稍好一些,跳跃更流畅并到达更高平台。但仍未能逃过第四个管道附近的坑洞——游戏结束。
Claude 3.7:超级马里奥神童?
与OpenAI和谷歌的模型不同,Claude 3.7玩得像个真人玩家。
- ✔ 只在必要时跳跃(躲避障碍或沟壑)

- ✔ 通过精准跳跃躲避敌人

- ✔ 发现了隐藏的星星道具!
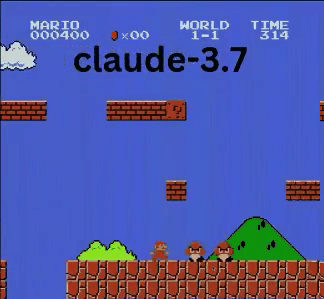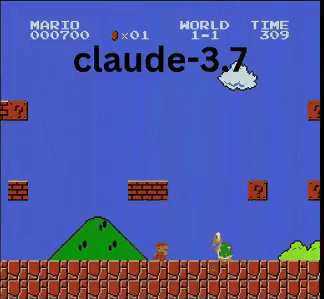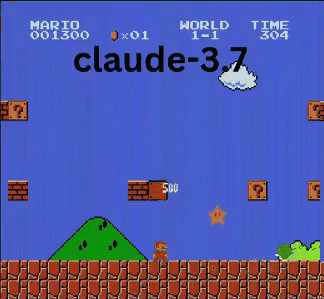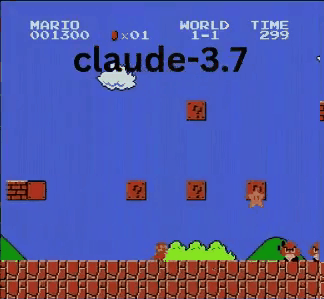
- ✔ 相比其他AI到达了最远点
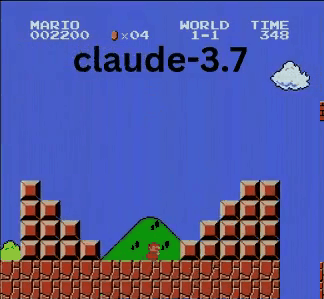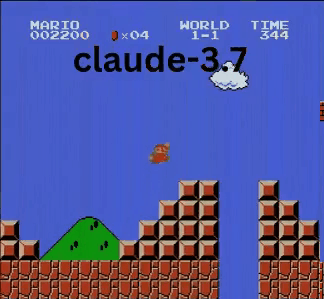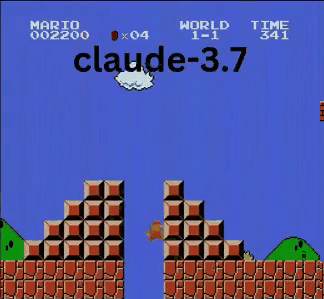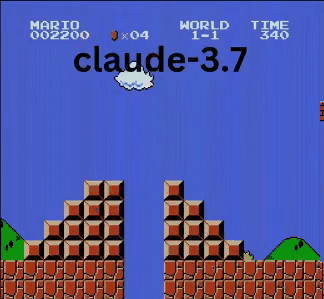
Claude 3.7甚至击败了此前保持最佳记录的Gemini 2.0 Flash。当Gemini在坑洞失败时,Claude不仅成功通过,还获取了额外金币,并迎战了板栗仔等新敌人。
AI能掌握更复杂的游戏吗?
马里奥并非唯一测试。研究人员还在需要战略决策的经典解谜游戏俄罗斯方块和2048上评估了AI模型。
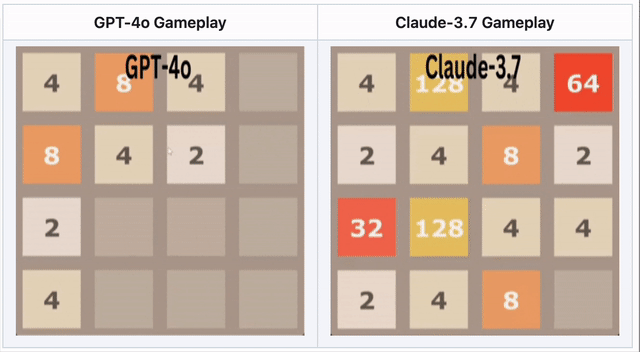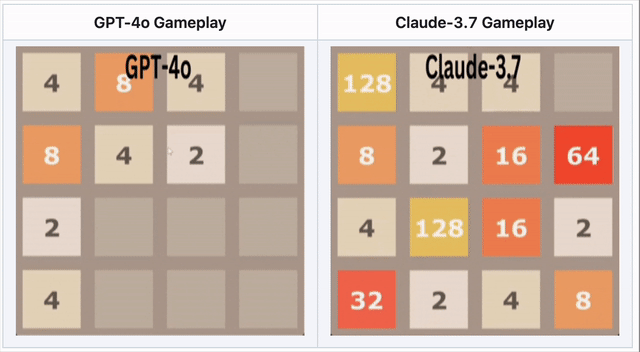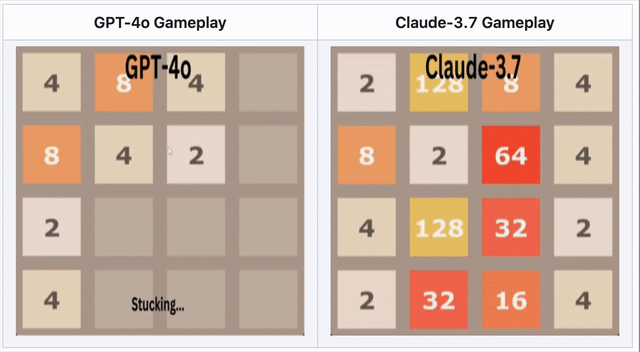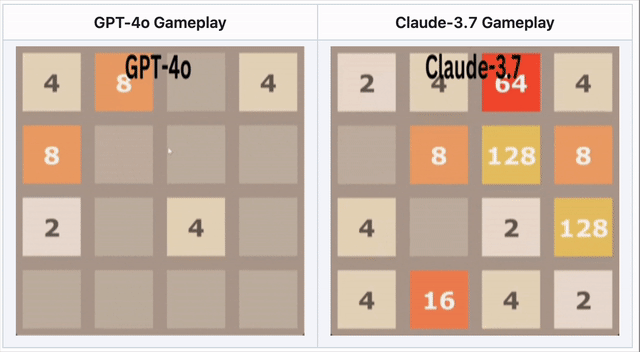
GPT-4o在2048中失败——Claude 3.7表现更优
在数字合并游戏2048中,AI需要滑动方块并做出战略移动。
🔹 GPT-4o因过度思考而早早失败
🔹 Claude 3.7坚持更久,做出更聪明的方块合并
🔹 两者都未获胜——但Claude胜过GPT-4o
Claude 3.7的俄罗斯方块表现惊艳专家
在俄罗斯方块测试中,Claude 3.7展现出:
✔ 合理的方块堆叠策略
✔ 正确消除整行
✔ 比其他AI模型存活更久
Anthropic的Alex Albert称赞该实验:
“我们应该把所有电子游戏都变成AI基准测试!”
游戏是AI评估的未来吗?
这些结果表明电子游戏可能成为AI的下一个重大基准。与传统测试不同,游戏需要实时决策、适应能力和运动技能。
随着AI模型快速发展,静态基准可能已不足以判断真正的智能。如果游戏被证明是更好的衡量标准,我们可能会看到AI模型在部署前通过强化学习在数千款游戏中训练。
最终思考:Claude本轮胜出,但未来如何?
Claude 3.7的卓越游戏表现暗示其相比GPT-4o和Gemini具有更强的推理和适应能力。但随着AI进化,哪个模型会率先像人类一样通关完整游戏?
随着开源游戏代理的推出,预计很快会出现更多AI对战电子游戏的案例。谁知道呢?也许有天AI会零失误通关超级马里奥——甚至击败人类电竞选手。
在那之前,Claude仍是AI游戏之王——而GPT-4o需要好好练习!









