




人工知能の世界では、多くの企業がオープンソース化の是非に悩んでいます。しかしアリババの技術チームは大胆な前進を続け、最先端のビデオ生成モデル「WanXiang」を公開しました。このオープンソースモデルには推論コードと重みパラメータが完全に含まれるだけでなく、最も柔軟なオープンソースライセンスが適用されています。
ビデオ生成の課題
ビデオ生成モデルに詳しい方なら、いくつかの根本的な課題があることをご存知でしょう。例えば、体操の宙返りやダンスの連続動作など、複雑な人体の動きを正確に再現できないモデルが大半です。物体同士の跳ね返りや相互作用のリアルさも不安定で、長文プロンプトでは指示の一部しか反映されない「選択的遵守」が発生しがちです。これら3つの領域を全てクリアしたモデルがオープンソース化される例は極めて稀です。

アリババのアプローチ
しかしWanXiangモデルは異なるアプローチを採用しています。回転動作や宙返り、ジャンプといった複雑な動きを捉えるだけでなく、衝突・反発・切断といった物理現象を忠実に再現。英語と中国語の長文プロンプトを正確に解釈し、シーンの遷移やキャラクターの相互作用まで生成可能です。 
公式デモンストレーションを見てみましょう:
デモ1:ダイビング動作
プロンプト: 赤い水泳パンツを着た男性が飛び込み台からプロのダイビング技を披露。空中で逆さまになり、腕を伸ばし足を揃えた姿勢でプールに飛び込む。カメラアングルが変化し、青い背景に水しぶきが上がる様子

デモ2:馬術競技
プロンプト: プロの装備を着た騎手が障害物飛越コースを馬と共に進む。騎手は集中した表情で、馬は各障害を正確に飛び越える。自然な屋外背景でダイナミックな緊張感を表現

デモ3:猫のボクシングマッチ
プロンプト: 明るいリングで擬人化した2匹の猫がボクシングギアを着て激しく戦う。素早い動き、強烈なパンチ、鮮明なアクション詳細を表現

WanXiangの実用性
「高スペック環境でしか動かないならオープンソース化の意味は?」という疑問には、14B(140億)と1.3B(13億)パラメータの2バージョンが回答します。14B版は高性能を追求していますが、1.3B版は4090などのコンシューマー向けGPUで動作可能。VRAM使用量8.2GB以下で480P
萬象の主な特徴
1. テキストからビデオへの生成
「テキストからビデオ」機能は萬象の代表的な能力です。簡単に言えば、テキストプロンプトを高品質な動画に変換できます。例えば、単なる説明文から映画レベルの特殊効果、特殊フォント、アニメーションロゴまでも生成可能です。この柔軟性が他のモデルとの差別化要因です。
- 例: ネオン輝く都市景観の中、「Welcome」の文字がサイバーパンク風の鮮やかな背景に浮かび上がる

2. 複雑なモーション生成
複雑な動きは動画生成モデルにとって最大の課題です。回転、跳躍、走行といった動作でも、わずかな不自然さがリアリティを損ないます。しかし萬象はこの領域で優れた精度を発揮します。
- 例1: バスケットボール選手がジャンプシュート。選手の跳躍からボールの軌道まで正確に再現

- 例2: 燃えるバンの前を道化師が通り過ぎる。大げさな身振りと表情を映画的に表現

3. 長文指示への対応
萬象は単純な短いプロンプトだけでなく、長文記述に基づく詳細なシーン生成が可能。複数の被写体とアクションの整合性を維持します。
- 例: 多様なダンサー、鮮やかな装飾、祭典の雰囲気が広角ショットで表現された活気あるパーティーシーン

4. 物理シミュレーション
現実的な物理的相互作用の再現能力も特徴です。例えば透明な牛乳瓶を倒す際の液体の流れや表面張力を正確にシミュレートします。
- 例: 水入りグラスにイチゴが落下。水滴の物理現象と果実の動きを微細に再現

中核技術革新
WanXiangの強力なパフォーマンスは、効率的な因果的3D VAE(変分オートエンコーダ)とビデオ拡散トランスフォーマー(DiT)という2つの主要なイノベーションに由来します。
1. 効率的な因果的3D VAE
アリババのチームは、ビデオ生成に特化した新しい3D VAEアーキテクチャを設計しました。この革新により、時間と空間のより効率的な圧縮が可能になり、メモリ使用量を削減し、ビデオ内のイベントの流れを維持するために重要な時間的因果関係を確保します。
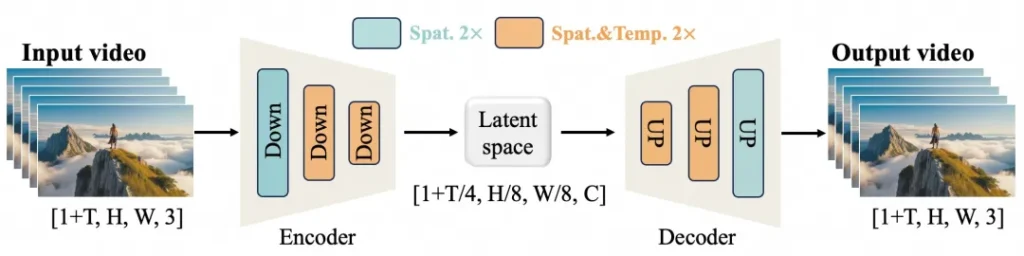
2. ビデオ拡散トランスフォーマー
WanXiangは最先端の拡散トランスフォーマー(DiT)アーキテクチャも採用しています。このアプローチは完全な注意メカニズムを活用して、長期的な空間的・時間的依存関係をモデル化します。線形ノイズ軌跡に基づくモデルアーキテクチャは、一貫した時空間整合性を持つビデオ生成を支援します。
オープンソースモデルの未来
今回のリリースにより、アリババのWanXiangモデルはビデオ生成の新たな基準を確立し、オープンソースモデルがクローズドソースモデルを凌駕できることを実証しました。Qwen言語モデルなどアリババの他のオープンソース活動と相まって、これはAI開発における重要な転換点を示しています。
これらの強力なモデルをオープンソース化することで、アリババはAIイノベーションの最前線に位置付けました。WanXiangを含むこれらのモデルは現在、GitHub、HuggingFace、MoDaなどのプラットフォームで公開され、学術研究から商業ビデオ制作まで幅広いユースケースをサポートしています。
結論
WanXiangのリリースはAIビデオ生成の状況を一変させるものです。テキストプロンプトからの詳細な高品質ビデオ作成、複雑な動きのシミュレーション、現実的な物理モデリング能力により、広告、映画、ゲーム産業に革命をもたらす可能性を秘めています。アリババのオープンソースAIへのコミットメントは障壁を打破し、ビデオ創作の世界で可能なことの新たな基準を設定しています。









