




인공지능 분야에서 많은 기업들은 여전히 오픈소스 전략 채택 여부를 고민하고 있습니다. 하지만 알리바바 기술팀은 과감한 행보를 이어가며 최근 첨단 비디오 생성 모델 ‘완샹(WanXiang)’을 공개했습니다. 이 오픈소스 모델은 추론 코드와 가중치 전체를 포함할 뿐만 아니라 가장 유연한 오픈소스 라이선스를 제공합니다.
비디오 생성의 도전 과제
비디오 생성 모델에 익숙한 이라면 몇 가지 기술적 한계를 알고 있을 것입니다. 예를 들어 대부분 모델은 체조 공중제비나 댄스 동작 같은 복잡한 인간 움직임을 정확히 구현하는 데 어려움을 겪습니다. 또한 물체 간의 충돌이나 반응 같은 현실적인 상호작용 구현은 운에 맡겨야 하는 경우가 많죠. 긴 텍스트 프롬프트를 입력해도 모델이 지시사항의 일부만 선택적으로 따르는 ‘선택적 준수’ 현상이 빈번합니다. 이 세 가지 영역을 모두 완벽히 구현한 모델이 오픈소스로 공개되는 경우는 극히 드뭅니다.

알리바바 완샹의 접근법
하지만 알리바바의 완샹 모델은 차별화된 접근 방식을 취하고 있습니다. 회전, 공중제비, 점프 같은 복잡한 동작을 구현할 뿐 아니라 충돌, 반발, 절단 같은 물리적 현상도 현실감 있게 재현합니다. 영어와 중국어 장문 프롬프트를 모두 처리할 수 있으며, 정확한 해석을 통해 해당 장면 전환과 캐릭터 상호작용을 구현해냅니다. 
공식 데모 영상을 몇 가지 살펴보겠습니다:
데모 1: 다이빙 액션
프롬프트: 레드 수영복을 입은 남성이 다이빙대에서 전문 다이빙 기술을 선보입니다. 공중에서 몸을 뒤집은 채 팔을 뻗고 다리를 모은 자세로 수영장에 뛰어들며 파란 배경에 물보라를 일으키는 장면을 카메라 앵글 변화와 함께 구현

데모 2: 마술 경기
프롬프트: 전문 장비를 착용한 기수가 장애물 넘기 경기장에서 말을 유능하게 조종하는 장면. 말이 각 장애물을 인상적인 정확도로 부드럽게 뛰어넘는 동작 구현, 자연스러운 야외 배경과 함께 역동적이고 긴장감 넘치는 장면 연출

데모 3: 고양이 복싱 매치
프롬프트: 밝게 조명된 링 안에서 복싱 장비를 입은 의인화된 두 마리 고양이가 치열한 경기를 펼치는 장면. 빠른 움직임과 강력한 펀치, 생생한 액션 디테일 구현

완샹의 실제 적용 가능성
일반 하드웨어에서 구동조차 불가능한 오픈소스 비디오 생성 모델이 무슨 의미가 있냐는 의문이 들 수 있습니다. 다행히 알리바바 모델은 14B와 1.3B 두 가지 버전으로 제공됩니다. 대규모 14B 버전은 고성능을 목표로 개발되었지만, 1.
완샹의 주요 기능
1. 텍스트-비디오 변환
“텍스트-비디오” 기능은 완샹의 차별화된 강점입니다. 간단한 텍스트 프롬프트만으로 고품질 영상을 생성할 수 있으며, 예를 들어 설명문 하나로 영화 수준의 시각 효과, 특수 타이포그래피, 애니메이션 로고 등을 구현합니다. 이러한 유연성은 타 모델과 차별화되는 요소입니다.
- 예시: 네온 불빛이 어우러진 도시 풍경에서 사이버펑크 배경 위 ‘Welcome’ 문구가 간판에 나타나는 모습

2. 복잡한 동작 구현
회전, 점프, 달리기 등 복잡한 움직임 구현은 영상 생성 모델의 최대 난제입니다. 사소한 오류만으로도 현실감이 무너질 수 있지만, 완샹은 이 분야에서 탁월한 정확도를 보여줍니다.
- 예시 1: 농구 선수가 점프 슛을 시도하는 장면. 선수의 점프 동작부터 공의 궤적까지 정확하게 재현

- 예시 2: 불타는 밴 앞을 지나가는 광대의 과장된 동작과 표정 연기를 영화적 스타일로 포착

3. 장문 지시 처리
완샹은 간단한 단문뿐만 아니라 긴 텍스트 설명을 기반으로 세부적인 장면을 생성할 수 있으며, 다중 객체와 액션 간의 일관성을 유지합니다.
- 예시: 다양한 댄서, 화려한 장식, 축제 분위기가 어우러진 와이드 앵글 파티 장면

4. 물리 현상 모델링
투명 유리컵에 담긴 우유를 기울이는 상황에서 액체의 흐름과 표면 장력을 정확하게 시뮬레이션하는 등 현실적인 물리적 상호작용 구현 능력이 뛰어납니다.
- 예시: 물잔에 떨어지는 딸기의 움직임. 물방울의 물리적 특성과 과일의 하강 과정을 생생하게 재현

핵심 기술 혁신
완샹의 강력한 성능은 두 가지 핵심 혁신에서 비롯됩니다: 효율적인 인과적 3D VAE(변형 오토인코더)와 비디오 디퓨전 트랜스포머(DiT).
1. 효율적인 인과적 3D VAE
알리바바 팀은 비디오 생성에 특화된 새로운 3D VAE 아키텍처를 설계했습니다. 이 혁신은 시간과 공간을 더 효율적으로 압축하여 메모리 사용량을 줄이고 시간적 인과성을 보장하며, 이는 비디오 내 이벤트 흐름 유지에 중요합니다.
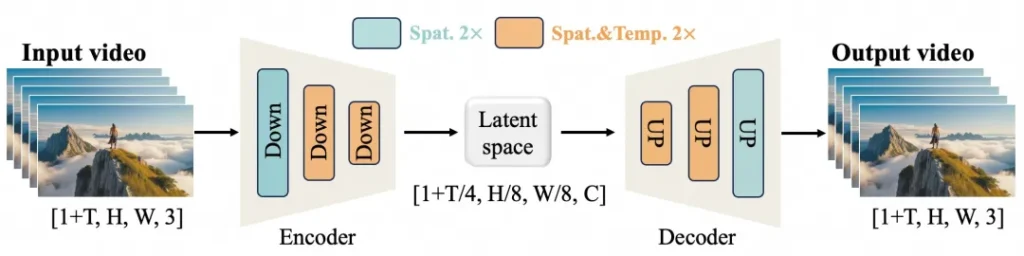
2. 비디오 디퓨전 트랜스포머
완샹은 최첨단 디퓨전 트랜스포머(DiT) 아키텍처를 활용합니다. 이 접근법은 장기적인 공간적·시간적 의존성을 모델링하기 위해 완전 주의 메커니즘을 사용합니다. 선형 노이즈 궤적에 기반한 모델 아키텍처는 일관된 시공간 정렬을 가진 비디오 생성에 도움을 줍니다.
오픈소스 모델의 미래
이번 출시로 알리바바의 완샹 모델은 비디오 생성 분야의 새로운 표준을 세웠으며, 오픈소스 모델이 클로즈드소스 모델을 능가할 수 있음을 입증했습니다. Qwen 언어 모델과 같은 알리바바의 다른 오픈소스 프로젝트와 함께, 이번 움직임은 AI 발전사에서 중요한 순간을 기록했습니다.
이러한 강력한 모델들을 오픈소스화함으로써 알리바바는 AI 혁신의 최전선에 자리매김했습니다. 완샹을 포함한 이들의 모델은 현재 GitHub, HuggingFace, MoDa와 같은 플랫폼에서 이용 가능하며, 학술 연구부터 상업용 비디오 제작에 이르기까지 다양한 사용 사례를 지원합니다.
결론
완샹의 출시는 AI 비디오 생성 분야에 판도를 바꿀 게임 체인저입니다. 텍스트 프롬프트에서 세부적이고 고품질의 비디오를 생성하고 복잡한 모션을 시뮬레이션하며 현실적인 물리 현상을 모델링하는 능력으로 광고, 영화, 게임 산업까지 혁신할 준비가 되어 있습니다. 알리바바의 오픈소스 AI에 대한 헌신은 장벽을 허물고 비디오 창작 분야에서 가능성의 새로운 기준을 제시하고 있습니다.









